
网络爬虫之使用pyppeteer替代selenium完美绕过webdriver检测
1引言
曾经使用模拟浏览器操作(selenium + webdriver)来写爬虫,但是稍微有点反爬的网站都会对selenium和webdriver进行识别,网站只需要在前端js添加一下判断脚本,很容易就可以判断出是真人访问还是webdriver。虽然也可以通过中间代理的方式进行js注入屏蔽webdriver检测,但是webdriver对浏览器的模拟操作(输入、点击等等)都会留下webdriver的标记,同样会被识别出来,要绕过这种检测,只有重新编译webdriver,麻烦自不必说,难度不是一般大。
作为selenium+webdriver的优秀替代,pyppeteer就是一个很好的选择。
2 手动安装
通过pip使用豆瓣源加速安装pyppeteer:
pip install -i https://pypi.douban.com/simple pypeteer
按照官方手册,先来感受一下:
import asyncio from pyppeteer import launch async def main(): browser = await launch(headless=False) page = await browser.newPage() await page.goto('http://www.baidu.com/') await asyncio.sleep(100) await browser.close() asyncio.get_event_loop().run_until_complete(main())
pyppeteer第一次运行时,会自动下载chromium浏览器,时间可能会有些长。不过,我第一次运行时,直接报错:
ssl.SSLCertVerificationError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1056)
尝试多种方法无果,无奈只能手动下载,但手动下载的方法网上资料也几乎没有,让我来做这个先行者吧。
上面代码运行虽然报错,但是控制台前两行却提供了很有用的信息:
[W:pyppeteer.chromium_downloader] start chromium download.
Download may take a few minutes.
可以看到,下载功能是由pyppeteer.chromium_downloader模块完成的,那么我们进入这个模块查看源码。
在这个模块源码中,我们可以看到downloadURLs、chromiumExecutable等变量,很明显指的就是下载链接和chromium的可执行文件路径。我们重点关注一下可执行文件路径
chromiumExecutable: chromiumExecutable = { 'linux': DOWNLOADS_FOLDER / REVISION / 'chrome-linux' / 'chrome', 'mac': (DOWNLOADS_FOLDER / REVISION / 'chrome-mac' / 'Chromium.app' / 'Contents' / 'MacOS' / 'Chromium'), 'win32': DOWNLOADS_FOLDER / REVISION / 'chrome-win32' / 'chrome.exe', 'win64': DOWNLOADS_FOLDER / REVISION / 'chrome-win32' / 'chrome.exe', }
可见,无论在哪个平台下,chromiumExecutable都是由是4个部分组成,其中 DOWNLOADS_FOLDER 和 REVISION是定义好的变量:
DOWNLOADS_FOLDER = Path(__pyppeteer_home__) / 'local-chromium'
进一步查看可以发现:
__pyppeteer_home__ = os.environ.get('PYPPETEER_HOME', AppDirs('pyppeteer').user_data_dir) REVISION = os.environ.get('PYPPETEER_CHROMIUM_REVISION', __chromium_revision__)
所以,DOWNLOADS_FOLDER 和 REVISION都是读取对应环境变量设置好的值,如果没有设置,就使用默认值。我们来输出一下,看看默认值:
import pyppeteer.chromium_downloader print('默认版本是:{}'.format(pyppeteer.__chromium_revision__)) print('可执行文件默认路径:{}'.format(pyppeteer.chromium_downloader.chromiumExecutable.get('win64'))) print('win64平台下载链接为:{}'.format(pyppeteer.chromium_downloader.downloadURLs.get('win64')))
输出结果如下:
|
1
2
3
|
默认版本是:575458可执行文件默认路径:C:\Users\Administrator\AppData\Local\pyppeteer\pyppeteer\local-chromium\575458\chrome-win32\chrome.exewin64平台下载链接为:https://storage.googleapis.com/chromium-browser-snapshots/Win_x64/575458/chrome-win32.zip |
在使用上面代码的时候,你可以将win64换成你的平台就好了,有了上面的下载链接,这个时候就可以先开始下载着chromium浏览器(有些慢),然后继续往下看。
import os os.environ['PYPPETEER_HOME'] = 'D:\Program Files' import pyppeteer.chromium_downloader print('默认版本是:{}'.format(pyppeteer.__chromium_revision__)) print('可执行文件默认路径:{}'.format(pyppeteer.chromium_downloader.chromiumExecutable.get('win64'))) print('win64平台下载链接为:{}'.format(pyppeteer.chromium_downloader.downloadURLs.get('win64')))
输出如下:
|
1
2
3
|
默认版本是:575458可执行文件默认路径:D:\Program Files\local-chromium\575458\chrome-win32\chrome.exewin64平台下载链接为:https://storage.googleapis.com/chromium-browser-snapshots/Win_x64/575458/chrome-win32.zip |
特别提醒:上面设置环境变量的那一行,必须在导入pyppeteer这一行上面,否则设置无效。
上面这种方法你需要在每次使用pypeeteer之前通过这行代码设置一下,实在麻烦,所以,我还是更愿意直接在windows系统里面添加这个变量:
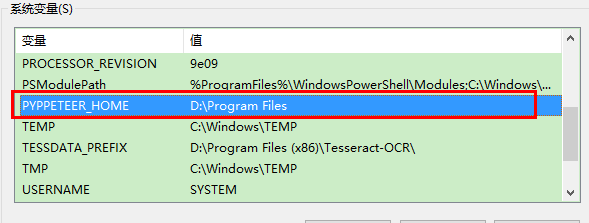
虽然我们把环境变量设置为D:\Program Files,但是层层文件夹之后,才到真正的可执行文件chrome.exe,下载好的压缩包解压后,所有文件都在名为chrome-win的文件夹中,所以,我们需要在D:\Program Files创建local-chromium\575458这两个文件夹(575458是上面的版本号,记得修改为你的版本号),然后将解压得到的chrome-win文件夹,重命名为chrome-win32,然后直接拷贝进去就好,整个安装过程就完成了。
再来试试最初(最上面)的代码,你会看到,已经可以成功运行。
我相信,大多数阅读这篇博文的读者都是用pyppeteer来开发爬虫(别说维护世界和平,我不信),那么接下来,重点来说说爬虫中要用到的一些主要操作。
3 主要操作
3.1 打开浏览器
打开浏览器是通过pyppeteer.launcher.launch(options: dict = None, **kwargs) 方法,运行该函数后,会得到一个pyppeteer.browser.Browser实例,也就是说浏览器对象实例。launch方法是必须使用的方法,所以,详细学学它的参数,你也直接阅读官方文档,因为我也是直接翻译的:
- ignoreHTTPSErrors (bool): 是否HTTPS错误,某人情况下为False.
- headless (bool): 是否以无头模式(无界面模式)执行,默认为True,为True时是不会弹出可视界面的,所以,上面代码运行时设置headless=False。注意,下面还有个devtools参数,表示是否出现打开调试窗口,如果devtools设置为True,headless就算设置为False也会弹出可视界面。
- executablePath (str): Chromium或Chrome浏览器的可执行文件路径,如果设置,则使用设置的这个路径,不使用默认设置.
- slowMo (int|float): 设置这个参数可以延迟pyppeteer的操作,单位是毫秒.
- args (List[str]): 要传递给浏览器进程的一些其他参数.
- ignoreDefaultArgs (bool): 如果有些参数你不想使用默认值,那么,通过这个参数设置,不过,孩子,最好别用,有危险(电脑会爆炸).
- handleSIGINT (bool): 是否响应 SIGINT 信号,是否允许通过快捷键Ctrl+C来终止浏览器进程,默认值为True,也就是允许.
- handleSIGTERM (bool): 是否响应 SIGTERM 信号,也就是说kill命令关闭浏览器,,默认值为True,也就是允许.
- handleSIGHUP (bool): 是否响应 SIGHUP 信号,即挂起信号,默认值为True,也就是允许.
- dumpio (bool): 是要将浏览器进程的输出传递给process.stdout 和 process.stderr 对象,默认为False不传递。
- userDataDir (str): 用户数据文件目录.
- env (dict): 以字典的形式传递给浏览器环境变量.
- devtools (bool): 是否打开调试窗口,上面介绍headless参数是说过,默认值为False不打开.
- logLevel (int|str): 日志级别,默认和 root logger 对象的级别相同.
- autoClose (bool): 当所有操作都执行完后,是否自动关闭浏览器,默认True,自动关闭.
- loop (asyncio.AbstractEventLoop): 时间循环。
- appMode (bool): Deprecated.
打开浏览器操作简单,看参数就行,不多介绍。
3.2 调整窗口大小
如果你运行了上面的代码,你会发现,打开的页面只在窗口左上角一小块显示,看着很别扭,这是因为pyppeteer默认窗口大小是800*600,所以,调整一下吧。调整窗口大小通过方法实现,看下面代码,最大化窗口:
import asyncio from pyppeteer import launch def screen_size(): """使用tkinter获取屏幕大小""" import tkinter tk = tkinter.Tk() width = tk.winfo_screenwidth() height = tk.winfo_screenheight() tk.quit() return width, height async def main(): browser = await launch(headless=False) page = await browser.newPage() width, height = screen_size() await page.setViewport({ # 最大化窗口 "width": width, "height": height }) await page.goto('http://www.baidu.com/') await asyncio.sleep(100) await browser.close() asyncio.get_event_loop().run_until_complete(main())
3.3 设置userAgent
常规操作,不多说,上代码:
import asyncio from pyppeteer import launch async def main(): browser = await launch(headless=False) page = await browser.newPage() # 设置请求头userAgent await page.setUserAgent('Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Mobile Safari/537.36') await page.goto('http://www.baidu.com/') await asyncio.sleep(100) await browser.close() asyncio.get_event_loop().run_until_complete(main())
3.4 执行js脚本
有时候,为了达成某些目的(例如屏蔽网站原有js),我们不可避免得需要执行一些js脚本。执行js脚本通过evaluate方法。如下所示,我们通过js来修改window.navigator.webdriver属性的值,由此绕过网站对webdriver的检测:
import asyncio from pyppeteer import launch async def main(): js1 = '''() =>{ Object.defineProperties(navigator,{ webdriver:{ get: () => false } }) }''' js2 = '''() => { alert ( window.navigator.webdriver ) }''' browser = await launch({'headless':False, 'args':['--no-sandbox'],}) page = await browser.newPage() await page.goto('https://h5.ele.me/login/') await page.evaluate(js1) await page.evaluate(js2) asyncio.get_event_loop().run_until_complete(main())
在上面代码中,通过page.evalute方法执行了两段js脚本,第一段脚本将webdriver的属性值设为false,第二段代码在此读取 webdriver属性值,输出为false。
3.5 模拟操作
pyppeteer提供了Keyboard和Mouse两个类来实现模拟操作,前者是用来实现键盘模拟,后者实现鼠标模拟(还有其他触屏之类的就不说了)。
主要来说说输入和点击:
import os os.environ['PYPPETEER_HOME'] = 'D:\Program Files' import asyncio from pyppeteer import launch async def main(): browser = await launch(headless=False, args=['--disable-infobars']) page = await browser.newPage() await page.goto('https://h5.ele.me/login/') await page.type('form section input', '12345678999') # 模拟键盘输入手机号 await page.click('form section button') # 模拟鼠标点击获取验证码 await asyncio.sleep(200) await browser.close() asyncio.get_event_loop().run_until_complete(main())
上面的模拟操作中,无论是模拟键盘输入还是鼠标点击定位都是通过css选择器,似乎pyppeteer的type和click直接模拟操作定位都只能通过css选择器(或者是我在官方文档中没找到方法),当然,要间接通过xpath先定位,然后再模拟操作也是可以的。下一小节中模拟登陆外卖平台就是用这种方法,不过,这种方法要麻烦一些,不推荐。
3.6 某电商平台模拟登陆
我曾经用selenium + chrome 实现了模拟登陆这个电商平台,但是实在是有些麻烦,绕过对webdriver的检测不难,但是,通过webdriver对浏览器的每一步操作都会留下特殊的痕迹,会被平台识别,这个必须通过重新编译chrome的webdriver才能实现,麻烦得让人想哭。不说了,都是泪,下面直接上用pyppeteer实现的代码:
import os os.environ['PYPPETEER_HOME'] = 'D:\Program Files' import asyncio from pyppeteer import launch def screen_size(): """使用tkinter获取屏幕大小""" import tkinter tk = tkinter.Tk() width = tk.winfo_screenwidth() height = tk.winfo_screenheight() tk.quit() return width, height async def main(): js1 = '''() =>{ Object.defineProperties(navigator,{ webdriver:{ get: () => false } }) }''' js2 = '''() => { alert ( window.navigator.webdriver ) }''' browser = await launch({'headless':False, 'args':['--no-sandbox'],}) page = await browser.newPage() width, height = screen_size() await page.setViewport({ # 最大化窗口 "width": width, "height": height }) await page.goto('https://h5.ele.me/login/') await page.evaluate(js1) await page.evaluate(js2) input_sjh = await page.xpath('//form/section[1]/input[1]') click_yzm = await page.xpath('//form/section[1]/button[1]') input_yzm = await page.xpath('//form/section[2]/input[1]') but = await page.xpath('//form/section[2]/input[1]') print(input_sjh) await input_sjh[0].type('*****手机号********') await click_yzm[0].click() ya = input('请输入验证码:') await input_yzm[0].type(str(ya)) await but[0].click() await asyncio.sleep(3) await page.goto('https://www.ele.me/home/') await asyncio.sleep(100) await browser.close() asyncio.get_event_loop().run_until_complete(main())
登录时,由于等待时间过长(我猜的)导致出现以下错误:
pyppeteer.errors.NetworkError: Protocol Error (Runtime.callFunctionOn): Session closed. Most likely the page has been closed.
在github上找到了解决方法,似乎只能改源码,找到pyppeteer包下的connection.py模块,在其43行和44行改为下面这样:
self._ws = websockets.client.connect( # self._url, max_size=None, loop=self._loop) self._url, max_size=None, loop=self._loop, ping_interval=None, ping_timeout=None)
再次运行就没问题了。可以成功绕过官方对webdriver的检测,登录成功,诸位可以自己尝试一下。