
如何识别图片文字,PaddleOCR机器学习开源项目使用 | 机器学习
什么是OCR?
光学字符识别(Optical Character Recognition, OCR),是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。简而言之,检测图像中的文本资料,并且识别出文本的内容。
那么有哪些应用场景呢?
其实我们日常生活中处处都有ocr的影子,比如在疫情期间身份证识别录入信息、车辆车牌号识别、自动驾驶等。我们的生活中,机器学习已经越来越多的扮演着重要角色,也不再是神秘的东西。
OCR的技术路线是什么呢?
ocr的运行方式如下图,输入->图像预处理->文字检测->文本识别->输出。

本文主要是介绍一个博主使用的比较好的OCR开源项目,在这里分享给大家——PaddleOCR。
项目Github地址: PaddleOCR地址
我会按照刚接触的状态,梳理一下验证使用该项目的过程。
项目使用
先把项目从github上clone下来,慢慢分析。
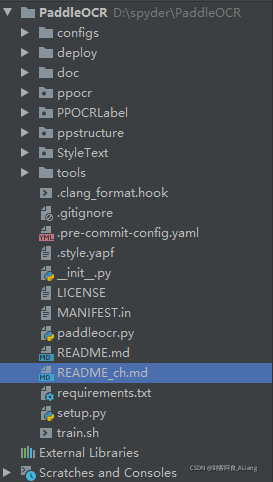
项目结构
首先我们看一下项目的构造。
环境部署

输入命令:
conda create -n paddle_env python=3.8
激活环境:
conda activate paddle_env
2、依赖包下载
paddlepaddle安装
pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
layoutparser安装
pip3 install -U https://paddleocr.bj.bcebos.com/whl/layoutparser-0.0.0-py3-none-any.whl
Shapely安装,这个需要下载,下载地址:Shapely下载地址
我选的是这个

安装命令:
pip install Shapely-1.8.0-cp38-cp38-win_amd64.whl
paddleocr安装
pip install paddleocr -i https://mirror.baidu.com/pypi/simple
好的,环境有点多,都安装好了就开始上手使用吧。
测试代码
官方给出了两种模式,一是命令行执行,一是代码执行。为了直观的看到配置,我这里使用的是代码模式。
准备一张带文字的图片

测试代码如下
!/user/bin/env python
# coding=utf-8
"""
@project : ocr_paddle
@author : huyi
@file : test.py
@ide : PyCharm
@time : 2021-11-15 14:56:20
"""
from paddleocr import PaddleOCR, draw_ocr
# Paddleocr目前支持的多语言语种可以通过修改lang参数进行切换
# 例如`ch`, `en`, `fr`, `german`, `korean`, `japan`
ocr = PaddleOCR(use_angle_cls=True, use_gpu=False,
lang="ch") # need to run only once to download and load model into memory
img_path = './data/2.jpg'
result = ocr.ocr(img_path, cls=True)
for line in result:
# print(line[-1][0], line[-1][1])
print(line)
# 显示结果
from PIL import Image
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='./fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
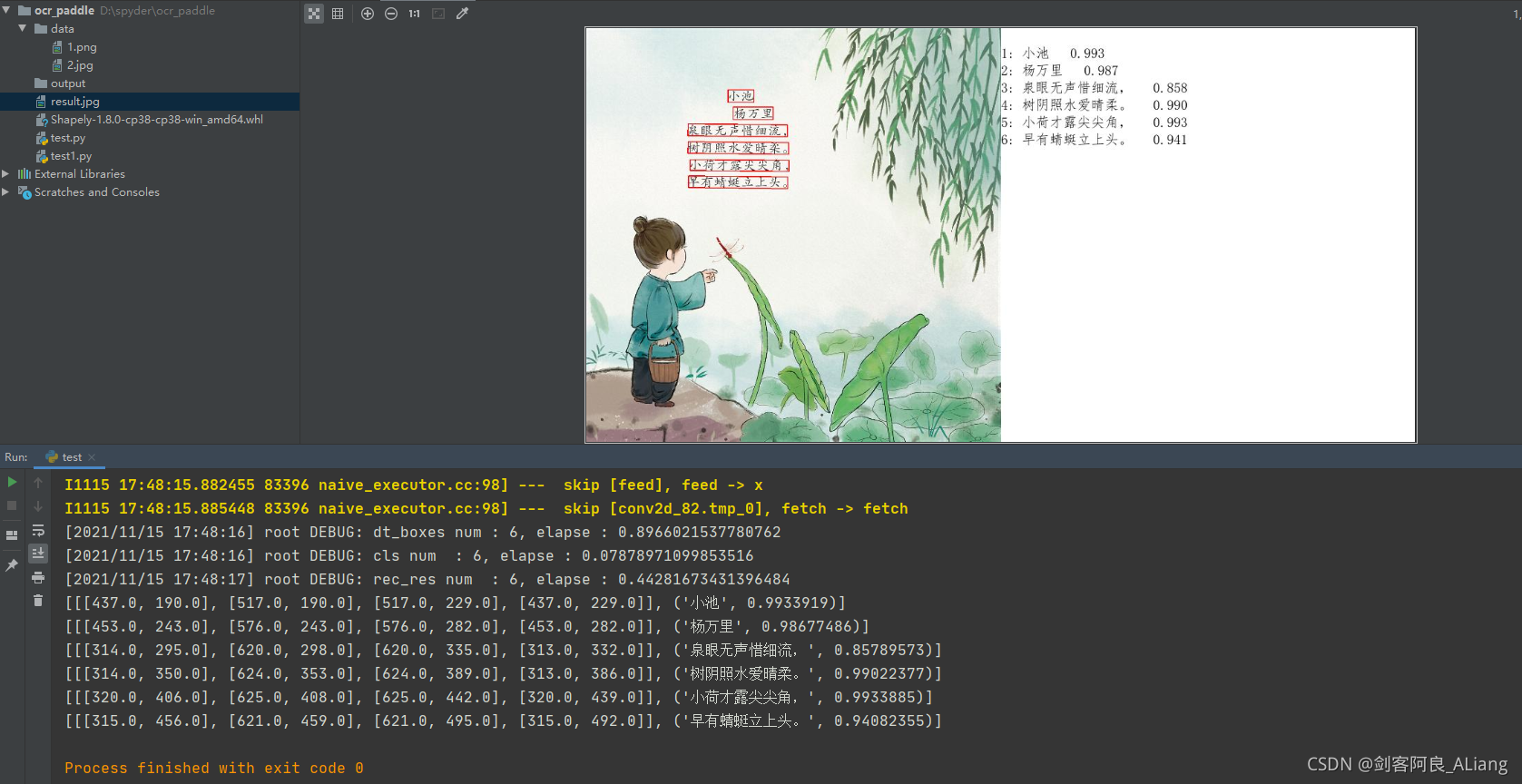
我们看到,打印的内容有识别出来的每句话所在的图片位置,以及识别结果和可信度。而上面的结果图中,将每句话对应的文字都框了出来。效果很不错!
参数补充
官方还给出了一些参数,可以调整输出的内容。可以参看quickstart.md文件。参数补充:
- 单独使用检测:设置`--rec`为`false`
- 单独使用识别:设置`--det`为`false`
官方还提供一个标准的json结构输出数据
PP-Structure的返回结果为一个dict组成的list,示例如下
```shell
[{ 'type': 'Text',
'bbox': [34, 432, 345, 462],
'res': ([[36.0, 437.0, 341.0, 437.0, 341.0, 446.0, 36.0, 447.0], [41.0, 454.0, 125.0, 453.0, 125.0, 459.0, 41.0, 460.0]],
[('Tigure-6. The performance of CNN and IPT models using difforen', 0.90060663), ('Tent ', 0.465441)])
}
]
```
总结
总的来说,这个项目还是很有意思的,训练的部分我就不多赘述了,毕竟准备数据挺麻烦的。回头我再想想这个项目可不可以魔改成好用的工具。