
图神经网络相似度计算
图神经网络相似度计算
注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark Flink Kafka Hbase Hive Flume等等~写的都是纯干货,各种顶会的论文解读,一起进步。
今天和大家分享一篇关于图神经网络相似度计算的论文
SimGNN: A Neural Network Approach to Fast Graph Similarity Computation
#博学谷IT学习技术支持#
前言
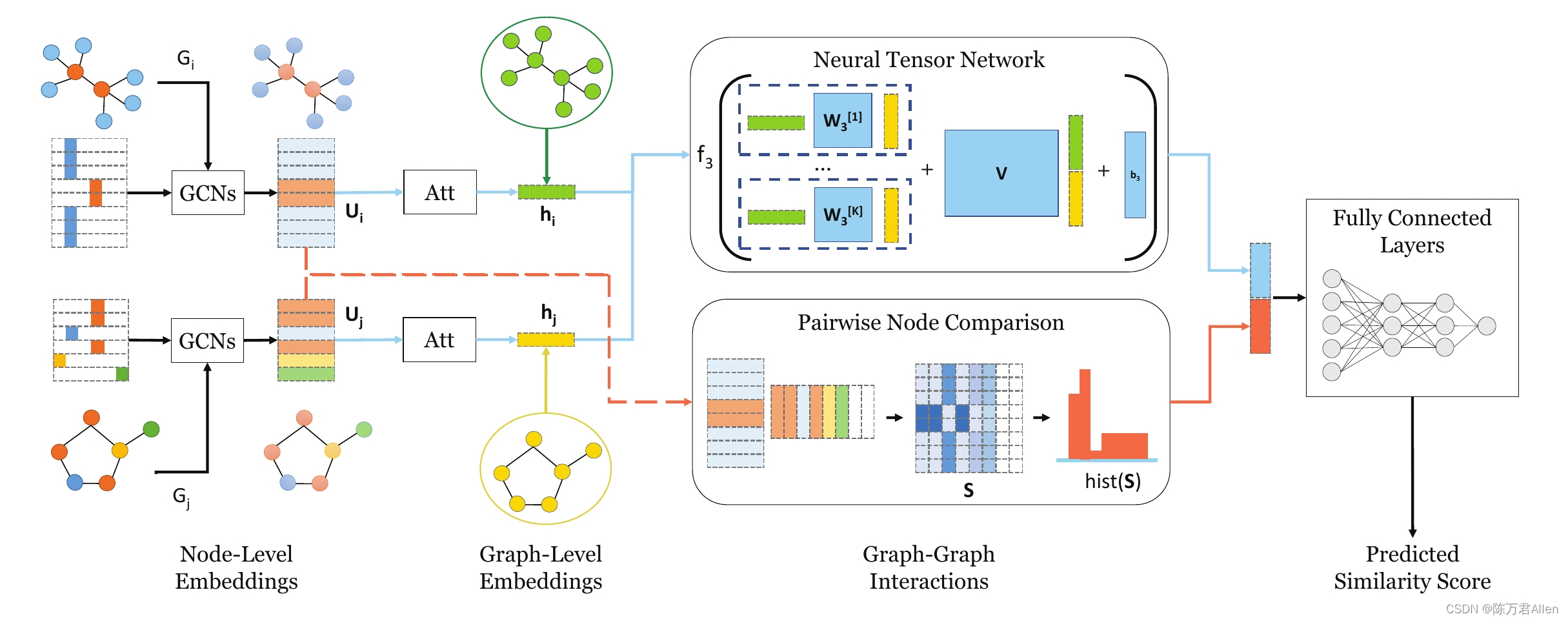
图神经网络是当下比较火的模型之一,使用神经网络来学习图结构数据,提取和发掘图结构数据中的特征和模式,满足聚类、分类、预测、分割、生成等图学习任务需求的算法。本文是主要通过图神经网络来对两个图的相似性进行快速打分的模型。
一、训练数据
本文采用torch内置数据集GEDDataset,直接调用就可以了,数据集一共有700个图,每个图最多有10个点组成,每个点由29种特征组成
代码如下(示例):
def process_dataset(self):
"""
Downloading and processing dataset.
"""
print("\nPreparing dataset.\n")
self.training_graphs = GEDDataset(
"datasets/{}".format(self.args.dataset), self.args.dataset, train=True
)
self.testing_graphs = GEDDataset(
"datasets/{}".format(self.args.dataset), self.args.dataset, train=False
)
二、模型的输入
每次输入两幅图,包含边的信息了,点的特征
代码如下(示例):
def forward(self, data):
edge_index_1 = data["g1"].edge_index
edge_index_2 = data["g2"].edge_index
features_1 = data["g1"].x
print(features_1.shape)
features_2 = data["g2"].x
print(features_2.shape)
batch_1 = (
data["g1"].batch
if hasattr(data["g1"], "batch")
else torch.tensor((), dtype=torch.long).new_zeros(data["g1"].num_nodes)
)
batch_2 = (
data["g2"].batch
if hasattr(data["g2"], "batch")
else torch.tensor((), dtype=torch.long).new_zeros(data["g2"].num_nodes)
)
三、图神经网络提取更新每个点的信息
这里运用直方图方式做特征比较新颖。
def convolutional_pass(self, edge_index, features):
"""
Making convolutional pass.
:param edge_index: Edge indices.
:param features: Feature matrix.
:return features: Abstract feature matrix.
"""
features = self.convolution_1(features, edge_index)
features = F.relu(features)
features = F.dropout(features, p=self.args.dropout, training=self.training)
features = self.convolution_2(features, edge_index)
features = F.relu(features)
features = F.dropout(features, p=self.args.dropout, training=self.training)
features = self.convolution_3(features, edge_index)
return features
#每个点都走三层gcn
abstract_features_1 = self.convolutional_pass(edge_index_1, features_1)
print(abstract_features_1.shape)
abstract_features_2 = self.convolutional_pass(edge_index_2, features_2)
print(abstract_features_2.shape)
四、计算点和点之间的关系得到直方图特征
def calculate_histogram(
self, abstract_features_1, abstract_features_2, batch_1, batch_2
):
abstract_features_1, mask_1 = to_dense_batch(abstract_features_1, batch_1)
abstract_features_2, mask_2 = to_dense_batch(abstract_features_2, batch_2)
B1, N1, _ = abstract_features_1.size()
B2, N2, _ = abstract_features_2.size()
mask_1 = mask_1.view(B1, N1)
mask_2 = mask_2.view(B2, N2)
num_nodes = torch.max(mask_1.sum(dim=1), mask_2.sum(dim=1))
scores = torch.matmul(
abstract_features_1, abstract_features_2.permute([0, 2, 1])
).detach()
hist_list = []
for i, mat in enumerate(scores):
mat = torch.sigmoid(mat[: num_nodes[i], : num_nodes[i]]).view(-1)
hist = torch.histc(mat, bins=self.args.bins)
hist = hist / torch.sum(hist)
hist = hist.view(1, -1)
hist_list.append(hist)
print(torch.stack(hist_list).view(-1, self.args.bins).shape)
return torch.stack(hist_list).view(-1, self.args.bins)
if self.args.histogram:
hist = self.calculate_histogram(
abstract_features_1, abstract_features_2, batch_1, batch_2
)
四、Attention Layer 得到图的特征
def forward(self, x, batch, size=None):
size = batch[-1].item() + 1 if size is None else size
mean = scatter_mean(x, batch, dim=0, dim_size=size)
transformed_global = torch.tanh(torch.mm(mean, self.weight_matrix))
coefs = torch.sigmoid((x * transformed_global[batch]).sum(dim=1))
weighted = coefs.unsqueeze(-1) * x
return scatter_add(weighted, batch, dim=0, dim_size=size)
pooled_features_1 = self.attention(abstract_features_1, batch_1)
pooled_features_2 = self.attention(abstract_features_2, batch_2)
五、运用NTN网络计算图和图之间的关系得到特征
def forward(self, embedding_1, embedding_2):
batch_size = len(embedding_1)
scoring = torch.matmul(
embedding_1, self.weight_matrix.view(self.args.filters_3, -1)
)
scoring = scoring.view(batch_size, self.args.filters_3, -1).permute([0, 2, 1]) #filters_3可以理解成找多少种关系
scoring = torch.matmul(
scoring, embedding_2.view(batch_size, self.args.filters_3, 1)
).view(batch_size, -1)
combined_representation = torch.cat((embedding_1, embedding_2), 1)
block_scoring = torch.t(
torch.mm(self.weight_matrix_block, torch.t(combined_representation))
)
scores = F.relu(scoring + block_scoring + self.bias.view(-1))
return scores
六、预测得到模型的结果
def process_batch(self, data):
self.optimizer.zero_grad()
data = self.transform(data)
target = data["target"]
prediction = self.model(data)
loss = F.mse_loss(prediction, target, reduction="sum")
loss.backward()
self.optimizer.step()
return loss.item()
总结
本文通过点和点的比较,加上图和图的比较,结合在一起,最后计算出两幅图的相似度。其中运用到GCN ,NTN,ATTENTION,直方图等方法。较为有创意。